Contents
See also: open-source project links.
Current projects and interests
Feature-flow and Valuenator
Feature flow is an agile practice that organizes work around units of value rather than time. This is based on experience applying two-tiered kanban at Zope Corporation.
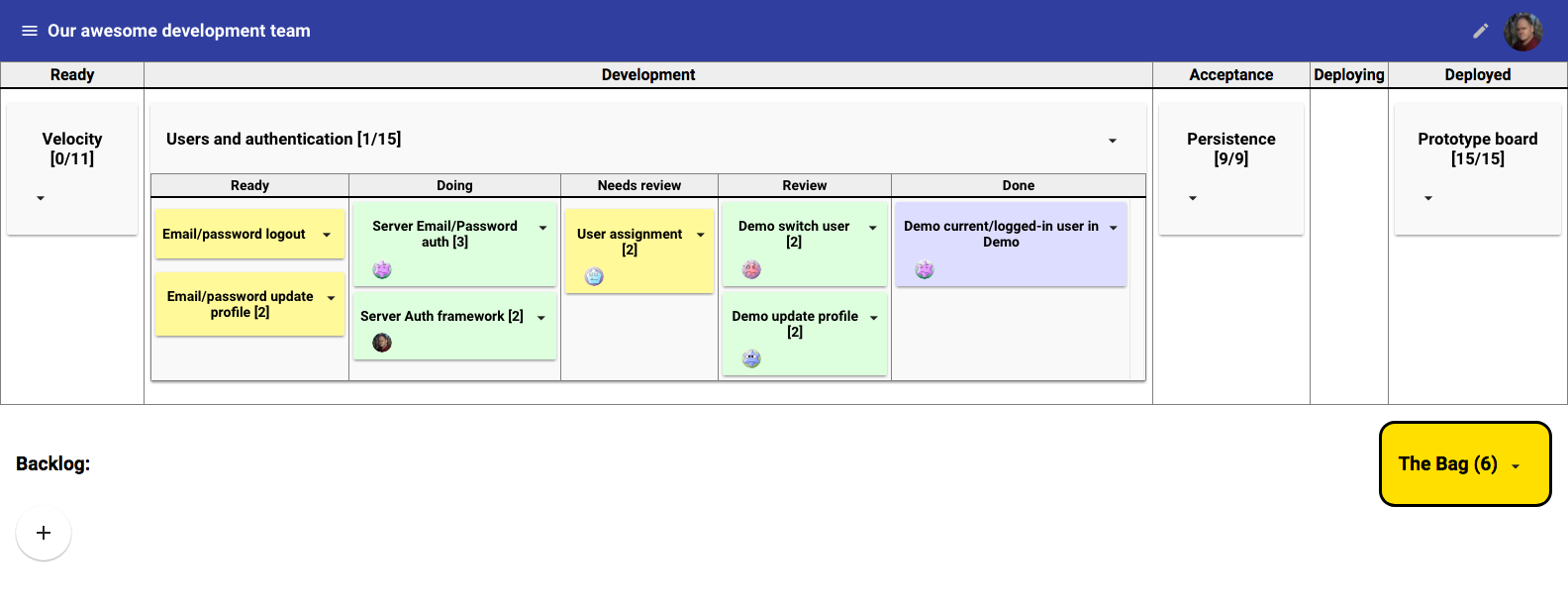
Originally, we implemented this using physical boards and later an implementation that used Asana as a backend. Physical boards were cumbersome and impractical for distributes teams. The Asana-based solution was eventually broken by changes in Asana's APIs, which weren't a great fit for this application in the first place (through no fault of Asana's).
After leaving Zope Corporation, I worked for an organization that would have benefited quite a bit from feature-flow and they were interested in trying it out, but there wasn't a suitable tool.
Recently I implemented a tool, Valuenator that automates the feature-flow process in an opinionated way.
Some interesting implementation details:
- React: React is awesome.
- Real-time UI: Generational Sets and Newt DB's follow API are used to provide a real-time UI.
- Demo version: A Demo version stores data locally in IndexedDB, allowing the application to be tried without installing or signing up for anything.
KARL, Open Society Foundations
KARL is a knowledge-management system used by the Open-Society Foundations. It's implemented using Pyramid and ZODB. Newt DB is used to store object data in PostgreSQL in both pickle and JSON formats. I've been converting queries from ZODB-based catalog queries to PostgreSQL queries using JSONB data managed by Newt DB. I've also been helping out with deployment and other issues.
This project has been a good test bed for Newt DB, as the queries are complex and provide interesting indexing challenges, due to the hierarchical nature of the data.
Newt DB
Newt DB combines the power and ease of use of ZODB, an object-oriented database for Python, with a document-oriented database based on PostgreSQL JSON (jsonb) support.
Newt DB addresses the biggest drawbacks of using ZODB:
Access limited to Python
Newt DB makes data available as JSON in PostgreSQL.
Searching
There are "catalog" frameworks built on ZODB that can be very fast, leveraging the powerful caching abilities of ZODB. However, they can greatly increase the number of objects in a database, add a lot of extra processing and application complexity.
With Newt DB, you can leverage PostgreSQL's powerful indexing and search capabilities. In most cases, this provides faster and more powerful searches and decreases the burden of search on the application.
ZODB
ZODB is an object-oriented database for Python. It provides highly transparent transactional object persistence with a pluggable storage back end.
Last year I rewrote the networking layer of ZEO to use asyncio and add SSL support. As part of this effort I simplified the ZEO and ZODB code quite a bit. It had (and still has, but less so) some over-done abstractions.
I've been wanting a much faster ZEO server for some time and I began that effort by creating a prototype ZEO server implemented using the Rust programming language.
I've also gotten more involved in the development of RelStorage. Development, and more importantly maintenance of RelStorage had languished, because the original developer lost interest. I arranged the hand over to Jason Madden and myself. Jason is the lead developer for RelStorage, but I've been able to make some contributions that have led to significant performance improvements, especially for PostgreSQL.
Upcoming projects include:
- Support for easy asynchronous update of external indexes for ZEO, using a transaction pub/sub capability built on ZRS. I recently released something similar for RelStorage with PostgreSQL.
- Better garbage collection.
- More work on the Rust-based byteserver.
- An implementation for JavaScript (?)
Buildout
Buildout is a build automation framework for Python. It's focus is on:
- Assembly of applications
- Assembles application components, invoking other builders, like make or distutils if necessary. The components may be Python libraries, configuration files, or applications.
- Project-oriented, rather than system package management for Python
- It automatically downloads and installs Python distributions into project, as opposed to system, locations as needed to satisfy Project requirements.
- Automation and reproducibility
- You can check a buildout out of a revision control system and build it it one or 2 commands and get a predictable result.
It provides an alternative package-installation model, using eggs and generated Python paths, that's similar to the way Java applications are assembled using jar files and generated class paths.
I recently added Python wheel support. Wheels are becoming the dominant distribution format for Python packages. Wheels also make binary distributions more practical, because they do a better job of capturing environment differences. This makes it much easier to install harder-to-build packages like numpy.
I recently embarked on a complete rewrite of the Buildout documentation. The original documentation was a collection of doctests. This was an experiment in reusing doctests as documentation. The result was pretty horrible documentation. The new documentation is written first as documentation. (The examples in the documentation are still tested, using manuel.) The new documentation also reflects years of changes, experience, and best practices.
Rust and Scala
In 2016, I used Rust for an experimental ZODB server. It provided significant performance improvements. Rust has an interesting run-time-free approach to safe memory management and a functional programming style that reminded me of Scala.
I used Scala actively from 2013-2015. I care about code readability. I was looking for a high-level clean language that provides better performance than Python [1]. I settled into a comfortable familiarity with it for Android development.
I wrote a Blob server for ZODB in Scala that let us (Zope Corporation) store blobs in S3. It would be fun to do more server work in Scala.
I was somewhat skeptical of the claim that statically typed languages pay for themselves (for the hassles of static typing) by reducing the need for tests, however, on one of our project, we decided to skimp on tests to move more quickly and I was pleased with the low error rates we had despite skimping on tests.
I haven't used Scala for over a year and miss it. I'm getting rather (um) rusty.
Projects I'm actively maintaining or contributing to
Zope Replication Services
Zope Replication Services (ZRS) provides replication of ZODB ZEO servers. ZRS has a fairly simple architecture and is straightforward to use. It uses Twisted for network communication.
bobo
Bobo is a very lightweight WSGI application framework.
This is the second incarnation of bobo. The first was a object publishing framework for the web, developed in 1996 that eventually grew into Zope and that inspired many other Python Web frameworks. The new bobo returns to the simplicity of the original bobo, while benefiting from more than 15 years of web-development experience.
A while back, I gave a Talk on bobo at the NoVA Python Meetup.
When I released Bobo, I made a conscious decision to not promote it, as I was weary of promotion (and counter-promotion) of web frameworks. I still am, however this was a mistake. Flask came out a year later and became the main Python micro-framework. I used Flask for almost a year and still prefer bobo because bobo is lighter-weight and provides a more pythonic API. Bobo, sadly gets very little attention and use.
I'm contemplating a Flask plugin that gives Flask some of bobo's features.
| [1] | Python is fast enough most of the time, and generally scaling horizontally is better than scaling vertically, but there are times where raw speed is valuable, especially when you really need to scale vertically, or where you need to minimize latency. Python executes more slowly than many other languages, and it doesn't make good use of multiple cores. |